While neural-based text to speech (TTS) models can synthesize natural and intelligible voice, they usually require high-quality speech data, which is costly to collect. In many scenarios, only noisy speech of a target speaker is available, which presents challenges for TTS model training for this speaker.
Previous works usually address the challenge in two ways: 1) training the TTS model using the speech denoised with an enhancement model; 2) taking a single noise embedding as input when training with noisy speech. However, they usually cannot handle noisy speech with complicated noise such as those with high variations along time.
In this paper, we develop DenoiSpeech, a TTS system that can synthesize clean speech for a speaker with only noisy speech. We carefully design a noise condition module that is jointly trained with the TTS model and can capture the fine-grained frame-level noise information. Experimental results show that DenoiSpeech can generate clean speech in complicated noisy situations.
Audio Samples
All of the audio samples use Parallel WaveGAN (PWG) as vocoder.
Artificial Noisy Speech Corpus
We use the VCTK corpus for speech information and the Nonspeech100 for background noise.
Comparison with Other Models
Did he trip?
Clean GT
Noisy GT
Enhancement-Based
Augment-Adversarial
DenoiSpeech
Celtic were the losers then.
Clean GT
Noisy GT
Enhancement-Based
Augment-Adversarial
DenoiSpeech
I saw the story, but that amount wouldn’t even pay my commission.
Clean GT
Noisy GT
Enhancement-Based
Augment-Adversarial
DenoiSpeech
Basically we lost the game because we were outplayed.
Clean GT
Noisy GT
Enhancement-Based
Augment-Adversarial
DenoiSpeech
Ablation Study
Did he trip?
DenoiSpeech
Without Noise Condition
Utterance-Level Noise Condition
Fixed Noise Extractor
Without Adversarial CTC Module
Basically we lost the game because we were outplayed.
DenoiSpeech
Without Noise Condition
Utterance-Level Noise Condition
Fixed Noise Extractor
Without Adversarial CTC Module
Short-Time Noise Case
Basically we lost the game because we were outplayed.
Clean GT
Noisy GT
Enhancement-Based
Augment-Adversarial
DenoiSpeech
Real-World Noisy Speech Corpus
I want to sit down first.
Noisy GT
DenoiSpeech
Augment-Adversarial
Enhancement-Based
Customers swarmed into the store.
Noisy GT
DenoiSpeech
Augment-Adversarial
Enhancement-Based
Arizona already had a law in place that prohibited state-funded abortions.
Noisy GT
DenoiSpeech
Augment-Adversarial
Enhancement-Based
Clinton poured cold water on such action.
Noisy GT
DenoiSpeech
Augment-Adversarial
Enhancement-Based
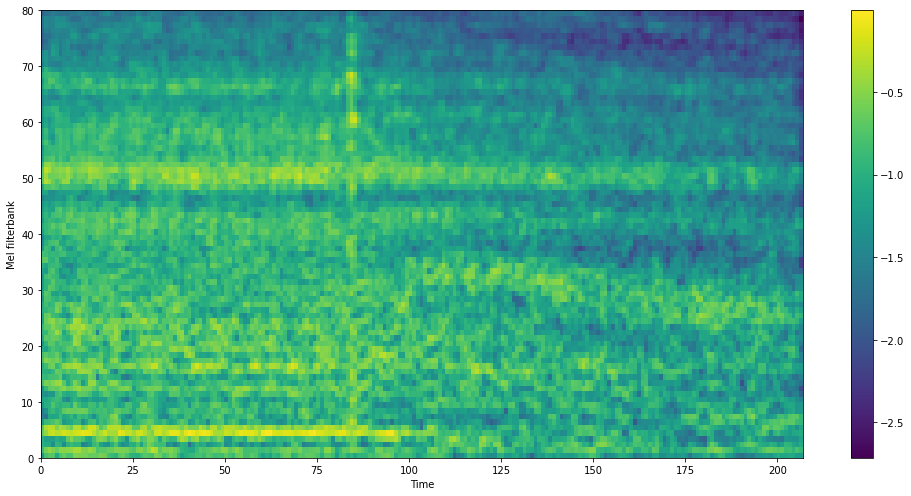
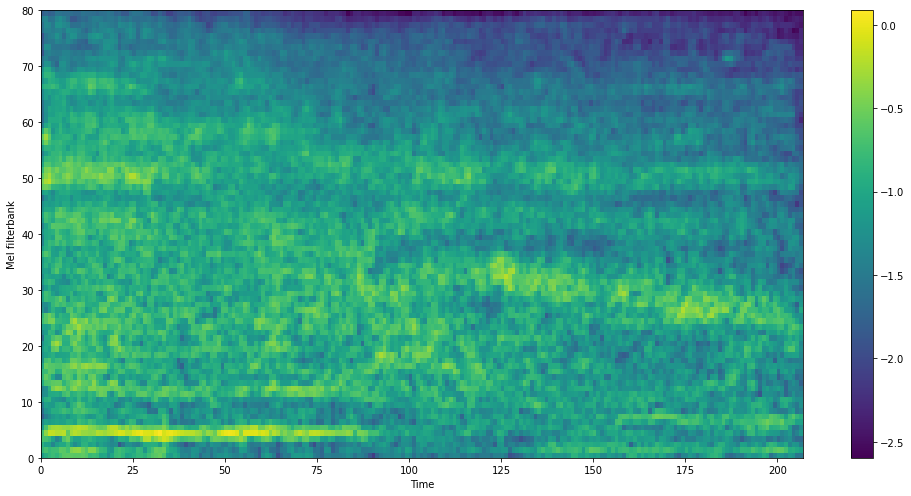
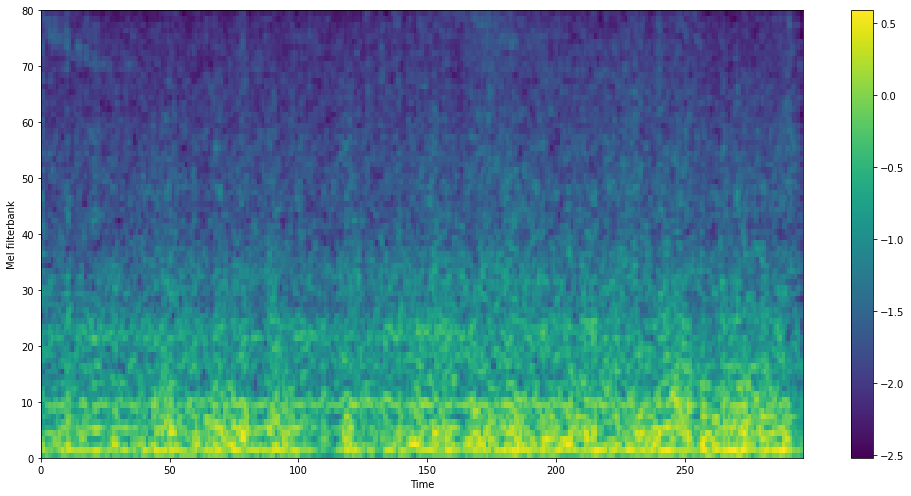
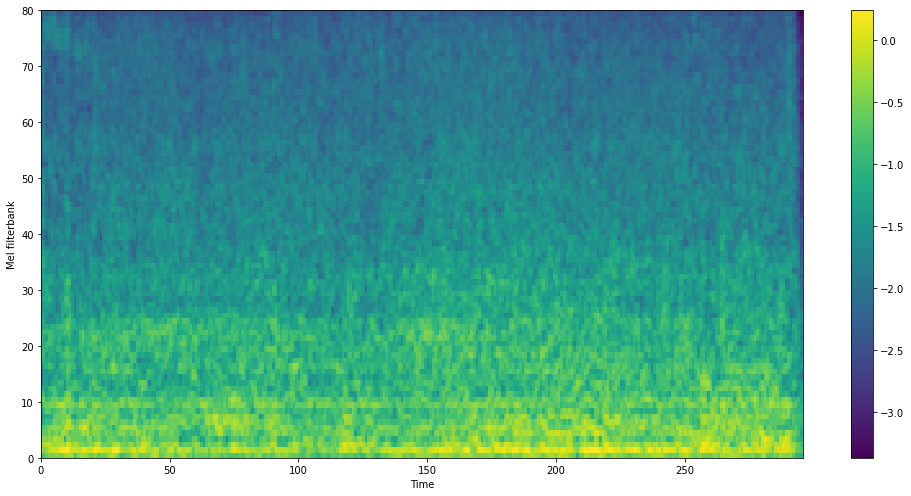
Visualization of Extracted Noise
Here are some comparisons of ground-truth noise and extracted noise by our noise extractor.
GT Noise
Extracted Noise
GT Noise
Extracted Noise
GT Noise
Extracted Noise
GT Noise
Extracted Noise
SMOS (Similarity MOS)
We randomly selected 12 utterances (which are all pronounced by a speaker) from the test set, and distributed them to 10 participants (native speakers). Each participant received the same 12 utterances with different orders and give the SMOS score (compared with Clean GT).