Neural network based end-to-end text to speech (TTS) has significantly improved the quality of synthesized speech. Prominent methods (e.g., Tacotron 2) usually first generate mel-spectrogram from text, and then synthesize speech from mel-spectrogram using vocoder such as WaveNet. Compared with traditional concatenative and statistical parametric approaches, neural network based end-to-end models suffer from slow inference speed, and the synthesized speech is usually not robust (i.e., some words are skipped or repeated) and lack of controllability (voice speed or prosody control). In this work, we propose a novel feed-forward network based on Transformer to generate mel-spectrogram in parallel for TTS. Specifically, we extract attention alignments from an encoder-decoder based teacher model for phoneme duration prediction, which is used by a length regulator to expand the source phoneme sequence to match the length of target mel-spectrogram sequence for parallel mel-spectrogram generation. Experiments on the LJSpeech dataset show that our parallel model matches autoregressive models in terms of speech quality, nearly eliminates the problem of word skipping and repeating in particularly hard cases, and can adjust voice speed smoothly. Most importantly, compared with autoregressive Transformer TTS, our model speeds up the mel-spectrogram generation by 270x and the end-to-end speech synthesis by 38x. Therefore, we call our model FastSpeech.
Audio Samples
All of the audio samples use WaveGlow as vocoder.
Audio Quality
I will quote an extract from the reverend gentleman’s own journal.
GT(WaveGlow)
Transformer TTS
FastSpeech
GT
Tacotron 2
Merlin
He is quite content to die
GT(WaveGlow)
Transformer TTS
FastSpeech
GT
Tacotron 2
Merlin
The result of the recommendation of the committee of 1862 was the Prison Act of 1865
GT(WaveGlow)
Transformer TTS
FastSpeech
GT
Tacotron 2
Merlin
The felons’ side has a similar accommodation, and this mode of introducing the beverage is adopted because no publican as such
GT(WaveGlow)
Transformer TTS
FastSpeech
GT
Tacotron 2
Merlin
He had prospered in early life, was a slop-seller on a large scale at Bury St. Edmunds, and a sugar-baker in the metropolis
GT(WaveGlow)
Transformer TTS
FastSpeech
GT
Tacotron 2
Merlin
Robustness Test
You can call me directly at four two five seven zero three seven three four four or my cell four two five four four four seven four seven four or send me a meeting request with all the appropriate information.
Transformer TTS
FastSpeech
To deliver interfaces that are significantly better suited to create and process RFC eight twenty one , RFC eight twenty two , RFC nine seventy seven , and MIME content.
Transformer TTS
FastSpeech
Http0XX , Http1XX , Http2XX , Http3XX
Transformer TTS
FastSpeech
Length Control
Voice Speed
was executed on a gibbet in front of his victim’s house.
0.50x
0.75x
1.00x
1.25x
1.50x
For a while the preacher addresses himself to the congregation at large, who listen attentively
0.50x
0.75x
1.00x
1.25x
1.50x
he put them also to the sword.
0.50x
0.75x
1.00x
1.25x
1.50x
The nature of the protective assignment.
0.50x
0.75x
1.00x
1.25x
1.50x
Breaking between words
as yet | no rules or regulations had been printed or prepared
Origin
Add Breaks
that he appeared to feel deeply the force of the reverend gentleman’s observations especially | when the chaplain spoke of
Origin
Add Breaks
after dinner | he went into hiding for a day or two
Origin
Add Breaks
the man bousfield however | whose execution was so sadly bungled
Origin
Add Breaks
here again | probably it was partly the love of notoriety which was the incentive
Origin
Add Breaks
Inference Speedup
The evaluation experiments are conducted on the server with 12 Intel Xeon CPU, 256GB memory and 1 NVIDIA V100 GPU.
Compared with autoregressive Transformer TTS, our model speeds up the mel-spectrogram generation by 270x and the end-to-end speech synthesis by 38x.
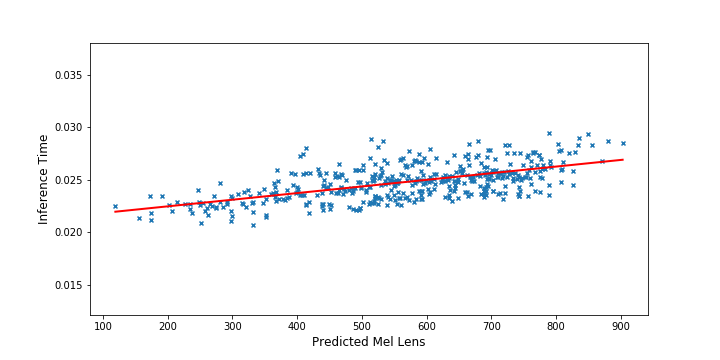
Inference Time vs. Mel Length (FastSpeech)
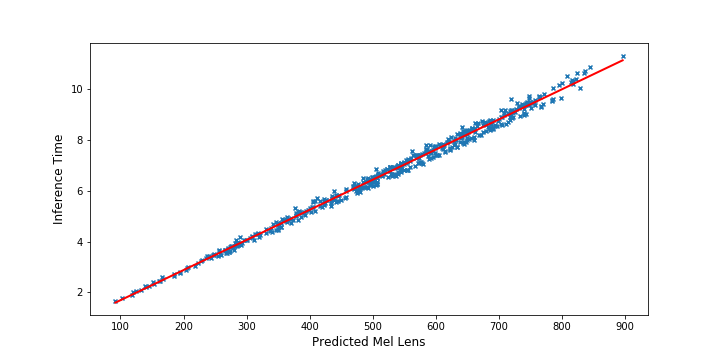
Inference Time vs. Mel Length (Transformer TTS)
We also visualize the relationship between the inference latency and the length of the predicted mel-spectrogram sequence in the test set. It can be found from Figure that the inference latency barely increases with the length of the predicted mel-spectrogram for FastSpeech, while increases largely in Transformer TTS. This indicates that the inference speed of our method is not sensitive to the length of generated audio due to parallel generation.